This blog post, I call blog posts like these “quick & dirty posts”, will show you today how to remove an ESXi host permanently from your vSAN cluster. Yes. Permanently. Forever.
Usually, you’re adding more capacity to a cluster, which means adding more hosts or disks to solve that problem. However, some legitimate reasons exist to remove an ESXi host from a vSAN cluster. Maybe you’re currently in the middle of a hardware renewal. The new hardware is already installed and running in production. And now, server by server, you’re removing the old hardware because you’re on track with the workload migration. The same counts for adding a cluster with nodes that have more “meat by the bone”, more compute power, and storage capacity. Nodes that are running more energy-efficient than the old ones. You see, only two reasons, but there might be many more.
But let’s dive into this topic now.
How to remove an ESXi host from a vSAN cluster?
We’re starting with making sure that the cluster and the disk groups have enough space to have one host removed. If the cluster is fine, let’s move on to remove the host.
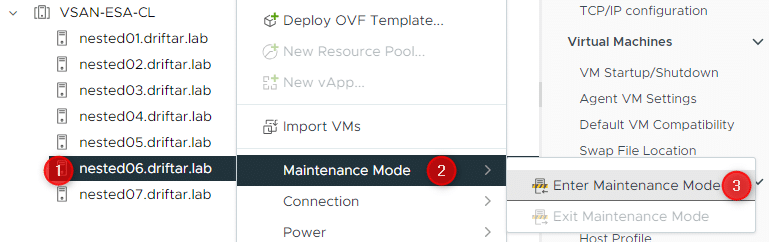
Place the host into maintenance mode
Right-click the host, choose “Maintenance Mode”, then “Enter Maintenance Mode”.
This blog post, I call blog posts like these “quick & dirty posts”, will show you today how to add an ESXi host to your vSAN cluster. You may need additional compute power, and/or storage capacity. Or you want to implement another storage policy to leverage storage efficiency and more failures to tolerate (RAID 5 / RAID 6 erasure coding). Maybe you want to create a stretched cluster, which needs an even number of vSAN nodes on each side plus a vSAN witness. So many reasons to add another vSAN node.
But let’s dive into this topic now.
How to add a new host to a vSAN cluster?
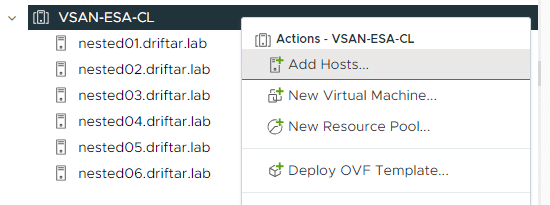
In my vSAN cluster, based on the Express Storage Architecture (ESA), I’ve got six hosts currently. I want to add another host to the cluster because of the computing and storage power. How to do this?
Right-click your cluster and choose “Add Hosts…”. So far, nothing special.
Just a few weeks ago, to my shame, I stumbled across an interesting feature in VMware vSphere when trying some things with vSAN. To be honest, and to make it clear before we dive into this topic in this blog post: I screwed up when I tested this feature the first time. Because I didn’t know about this feature and because I didn’t proceed as I should have, as per this feature. At the end I had to reinstall all my vSAN nodes and create a new clean environment after that I screwed up. It was somehow needed anyway because of the most recent homelab rebuild. So, somehow a win-win for me and the lab.
So don’t screw up! No, just kidding. you may know the feature better than me. And I can tell you, vSAN is stronger and more resilient than you may think.
In this blog post, I’d like to show you how to shut down a vSAN cluster, and how to start it again. The feature is hidden in plain view, right-click the vSAN cluster and you’re good to go. Or not?
In this blog post, I’m assuming that the vCenter is NOT running on the vSAN cluster. I may update this blog post, or create another one, with vCenter running on the cluster. Without searching the internet and checking the VMware docs, I don’t know by heart if this is even possible. Anyway. So how do you shut down the vSAN cluster?
When I’m doing blog posts based on my home lab, like the following article about a failed vSAN cache disk, then I’m really talking about a home lab. Most of the hard- and software configuration in a home lab isn’t supported, neither from VMware nor from any hardware vendor. There might be parts in my lab, for example, the base servers (DELL PowerEdge) or the Smart Array controllers (HPE), which are listed on the VMware HCL. But for example not my SSD (Samsung and Crucial), or probably any combination of controller and SSDs and/or base server. There are so many people out there in the IT, having homelabs and trying out new hard- and software, testing things and learning. If we build such labs then with the only reason to learn and understand how a certain technology works. Not to do fingerpointing to any vendor. If we blow up our labs, then it’s mostly our own fault, like having cheap disks (my bad because I can’t afford shiny Optane nor datacenter disks) or we’ve screwed the configuration of something. I will never, and I repeat, I will never blame any vendor if my lab blows up because of my fault.
Foreword
Recently I rebuilt my VMware home lab from scratch and with the most recent vSphere version available at this point. I planned to rebuild my lab a long time ago but because of my job and other things I really hadn’t the time to do that. But recently I had to rebuild my lab because I screwed up my vCenter. Yes, I screwed it. So what did that mean? Reinstall all and everything completely from scratch. All my physical ESXi hosts, domain controller, vCenter, Jumphost, and backup server. All these services are running on a standalone ESXi server with some local disks. This server is called my home base. I’ve got some more servers which are running my VMware vSAN environment. I reinstalled these too and reconfigured everything that was needed, like networking and storage.
This week one of my vSAN cluster nodes went into degraded mode because of one of the cache disks failed. I thought, easy, just replacing the cache disk and that’s it. But no, the struggle became real…
What happened?
I’ve got three DELL servers for my vSAN cluster. All servers are equipped with one SSD as cache tier and three SSDs for the capacity tier. Now one cache disk failed because of reasons (I really don’t know why). That was causing vSAN to go into degraded mode as “failures to tolerate” was set to 1. So one failure (the failed cache disk) was compensated. Just for your information in case you didn’t know. If a cache disk of one disk group fails, the whole disk group will become unavailable. In my case, that meant that one-third of the whole vSAN capacity was gone.
What did I to resolve this?
My first idea was to replace the failed cache disk as I’ve got some identical disks as spare drives available. Well, not directly as spare drives, but installed and configured as RAID 5 in my home base ESXi host. So I did a Storage vMotion on all my home base VMs mentioned above to another local RAID 5 datastore, deleted the SSD RAID datastore and removed the disks. The physical replacement of this disks was easy. But telling my degraded vSAN node to accept this disk was a different topic.
Checking the disks
After I installed the “new” disk into the vSAN node I did a rescan on all storage adapters. And there was nothing. Only the already existing capacity disks but no cache disk. So I tried the second and the third identical disk with the same result. Only the capacity disks were visible in vCenter on the host but not the cache disk. What’s wrong here? I knew that the ESXi server only shows empty disks without any volumes, file systems or data on it. But how should I wipe this disk when not even with esxcli the disk is not visible?
As I’m using HPE Smart HBA H240 as my storage controller in the DELL server, I already installed the HPE smart storage administrator CLI tool on all the vSAN nodes. So I was able to look into the storage controller to see what’s happening there (or probably not).
The following command showed me that all disks are here and are fine:
./ssacli ctrl slot=2 pd all show status
But I was still struggling. Why is vCenter still showing only the capacity disks?
Clearing the disk(s)
An article by Cormac Hogan showed me how to reclaim disks for other uses. So i deleted all the partitions on the existing capacity disks, hoping that then the cache disk will also come back online. I read on another blog that wiping all vSAN disks can bring back non-detected disks. But that didn’t help.
First I removed the vSAN node from the vSAN cluster:
esxcli vsan cluster leave
Next I checked with partedUtil how many and what kind of partitions are on the disks:
partedUtil get /vmfs/devices/disks/mpx.vmhba1:C2:T2:L0
Each capacity disks showed two partitions, so I wiped them all:
A look into the HPE smart storage administrator CLI tool again showed me that still all physical disks are here. A rescan on all HBA in vCenter on this particular host didn’t help, only the capacity disks were shown.
I looked a little deeper into the storage controller with the command:
./ssacli ctrl slot=2 pd all show detail
That showed something not completely unexpected:
physicaldrive 2I:0:1
Masked from HBA: The drive contains controller configuration data and has been disabled
in order to protect the configuration data. Please run the "modify clearconfigdata"
command on the drive to re-enable it.
This physical drive above was the cache disk I was missing in vCenter. OK, so let’s clear the “configdata” and let’s see what happens then:
I checked again with “all show detail” and this “modify clearconfigdata” was gone.
Now I was able to rescan all storage adapters in vCenter on this host and that brought back my missed cache disk:
But that was to easy…
After having my cache disk back I went into vSAN configuration in vCenter and claimed the disks. The small one for the cache tier, the bigger ones for the capacity tier. And boom! This particular disk group went into another network partition group. Well done, thank you for nothing!
When you search around the internet for vSAN network partition you will find many forum and blog posts mentioning that this happens if something with the network configuration wasn’t as good as it should be. In my case I checked everything and I changed nothing on the network. So this partitioning issue had another reason. But to be honest I didn’t try to solve that. I wasn’t in the mood for that. I only wanted to bring back my vSAN into a good and healthy state.
I removed this vSAN node from the cluster by just draggin and dropping it out of the cluster. Then I tried to remove it from the inventory. And another boom!
The resource 'eagle.lan.driftar.ch' is in use.
That was the error message in vCenter when I tried to remove the host from inventory. But why? The host is in maintenance mode! Dang it! Let me remove it!
After doing some research on the interwebs I checked also the tasks in vCenter if there is a bit more of information. And I’ve found something:
Cannot remove the host eagle.lan.driftar.ch because it's part of VDS vMotion-DSwitch vSAN-DSwitch.
Well, that’s true. And that was also the obvious reason why I can’t remove the host from inventory. So I had to reconfigure the host networking, putting back the VMKernel ports for vMotion and vSAN to their origin local virtual switches. After that I was finally able to remove the host from the inventory.
Now rebuilding vSAN…
The next steps were easy. I added the host back to the vSAN cluster and configured the VDS for vMotion and vSAN as they were before. Then I went into vSAN configuration and checked the disk group. Lucky me the disk group configured before was still there and healthy, and vSAN claimed it automatically. And no network partitioning this time! All hosts and disk groups in the same network partition group!
After retesting the health onf the vSAN cluster it showed that there is one component in need of a resync. One of my templates was partially on this disk group before failing and is now waiting until the resync completed.
But at least vSAN is working fine again!
Closing words
In the most cases, or probably in all cases, replacing a disk in vSAN should be easy. Usually you will replace a used disk against a new and empty disk other than me. But that doesn’t mean you can’t unless you know what to do. I’m glad if this blog post helped you solving the issue.
If you follow the steps described in the VMware Knowledge Base then you should be fine:
Oh boy, what a week! Some say that winter is now finally gone, nice and warm weather, not wearing winter jackets anymore. But hey, i’m not a weatherman. When you’re sitting in the office i think it doesn’t matter if it’s raining or snowing outside. Just kidding… Let’s get back to business.
There was some rumor about the next upcoming version. Will it be version 7? Or something just above 6.5? VMware did release several new products versions! And it’s all with version number 6.7. What a list! It’s one of those email notifications that I usually like to scroll down, a little more, and more and more, to get all the news soaked up like a sponge. I’d like to dive in right now and provide you a recap of this weeks VMware releases. And as i said, it’s quite a list. I’ll pick out just some new key features. You can find the full release news on the VMware Blogs (links provided here).
New product versions
vSphere 6.7
several new APIs that improve the efficiency and experience to deploy vCenter, to deploy multiple vCenters based on a template, to make management of vCenter Server Appliance significantly easier, as well as for backup and restore
significantly simplifies the vCenter Server topology through vCenter with embedded platform services controller in enhanced linked mode
2X faster performance in vCenter operations per second
vSphere 6.7 improves efficiency when updating ESXi hosts, significantly reducing maintenance time by eliminating one of two reboots normally required for major version upgrades (Single Reboot). In addition to that, vSphere Quick Boot is a new innovation that restarts the ESXi hypervisor without rebooting the physical host, skipping time-consuming hardware initialization
The HTML5-based vSphere Client provides a modern user interface experience that is both responsive and easy to use, and it’s now including other key functionality like managing NSX, vSAN, VUM as well as third-party components.
enabling encrypted vMotion across different vCenter instances
enhancements to Nvidia GRID vGPU
vSphere 6.7 introduces vCenter Server Hybrid Linked Mode, which makes it easy and simple for customers to have unified visibility and manageability across an on-premises vSphere environment running on one version and a vSphere-based public cloud environment, such as VMware Cloud on AWS, running on a different version of vSphere.
vSphere 6.7 also introduces Cross-Cloud Cold and Hot Migration
Delivers a new capability that is key for the hybrid cloud, called Per-VM EVC
vSAN 6.7 provides intuitive operations that align with other VMware products from a UI and workflow perspective to provide a “one team, one tool” experience
Iintroduces a new HTML5 UI based on the “Clarity” framework as seen in other VMware products (All products in the VMware portfolio are moving toward this UI framework)
A new feature known as “vRealize Operations within vCenter” provides an easy way for customers to see vRealize intelligence directly in the vSphere Client
vSAN 6.7 now expands the flexibility of the vSAN iSCSI service to support Windows Server Failover Clusters (WSFC)
vSAN 6.7 introduces an all-new Adaptive Resync feature to ensure a fair-share of resources are available for VM I/Os and Resync I/Os during dynamic changes in load on the system
Optimizes the de-staging mechanism, resulting in data that “drains” more quickly from the write buffer to the capacity tier. The ability to de-stage this data quickly allows the cache tier to accept new I/O, which reduces or eliminates periods of congestion
New health checks include:
Maintenance mode verification ensures proper decommission state
Consistent configuration verification for advanced settings
vSAN and vMotion network connectivity checks improved
Improved vSAN Health service installation check
Improved physical disk health check combines multiple checks (software, physical, metadata) into a single notification
vSphere Appliance Management Interface (VAMI) on port 5480 has received an update to the Clarity UI
There is now a tab dedicated to monitoring. Here you can see CPU, memory, network, database and disk utilization.
Another new tab called Services is also within the VAMI, giving the option to start, stop, and restart vCenter Server services if needed
vSphere 6.7 also marks the final release of the vSphere Web Client (Flash). Some of the newer workflows in the updated vSphere HTML5 Client release include:
new plugin for the vSphere Client. This plugin is available out-of-the-box and provides some great new functionality
When interacting with this plugin, you will be greeted with 6 vRealize Operations Manager (vROps) dashboards directly in the vSphere client
overview, cluster view, and alerts for both vCenter and vSAN views
The new Quick Start page is making it easier to get directly to the data you need to
four use cases: Optimize Performance, Optimize Capacity, Troubleshoot, and Manage Configuration
The Workload Optimization dashboard was updated. Workload Optimization takes predictive analytics and uses them in conjunction with vSphere Distributed Resource Scheduler (DRS) to move workloads between clusters. New with vROps 6.7, you can now fine tune the configuration for workload optimization
vROps 6.7 introduced a completely new capacity engine that is smarter and much faster
Developer and Automation Interfaces for vSphere 6.7
Added functionality to existing APIs in vSphere 6.7
Coverage of new areas
Appliance API updates: from prechecks to staging to installation and validation, it’s all available by API now
vCenter API updates: new APIs have been added to interact with the VM’s guest operating system (OS), viewing Storage Policy Based Management (SPBM) policies, and managing vCenter server services
also a handful of new APIs to handle the deployment and lifecycle of the vCenter server
a handful of updates to the vSphere Web Services (SOAP) APIs as well
Faster Lifecycle Management Operations in VMware vSphere 6.7
brand-new Update Manager interface which is now part of the HTML5 Client
Update Manager in vSphere 6.7 keeps VMware ESXi 6.0 to 6.7 hosts reliable and secure
the new UI provides a much more streamlined remediation process, requiring just a few clicks to begin the procedure. It’s not just a port from the old Flash client
Hosts that are currently on ESXi 6.5 will be upgraded to 6.7 significantly faster than ever before
Several optimizations have been made for that upgrade path, including eliminating one of two reboots traditionally required for a host upgrade
Quick Boot eliminates the time-consuming hardware initialization phase by shutting down ESXi in an orderly manner and then immediately re-starting it
include support for Persistent Memory (PMEM) and enhanced support for Remote Directory Memory Access (RDMA)
PMEM is a new layer called Non-Volatile Memory (NVM) and sits between NAND flash and DRAM, providing faster performance relative to NAND flash but also providing the non-volatility not typically found in traditional memory offerings
new protocol support for Remote Direct memory Access (RDMA) over Converged Ethernet, or RoCE (pronounced “rocky”) v2, a new software Fiber Channel over Ethernet (FCoE) adapter, and iSCSI Extension for RDMA (iSER)