Since few months i’m working with VMware vSAN in my own vSphere homelab. And i tell you, i really like vSAN! If you’re looking for an easy, affordable, very well performing and scalable storage solution, there you go. VMware vSAN is ready to take all your workloads. It doesn’t matter if it’s just your nested lab environment, or something more serious like a Virtual Desktop Infrastructure (VDI), big data or business critical applications like SQL databases and Microsoft Exchange servers.
How does vSAN work?
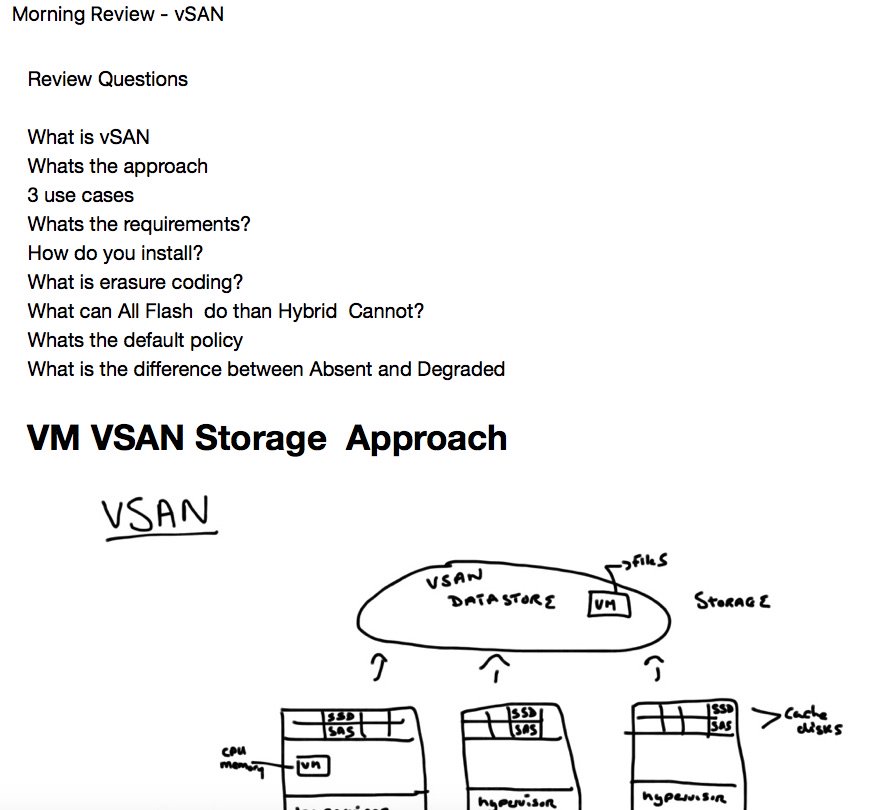
VMware vSAN takes the local disks of an ESXi hosts and puts them in a storage pool, a so called disk group. Put all disk groups of your ESXi hosts together in a cluster and you’ve got a vSAN datastore. It’s that easy. And it’s also easy to make changes to those disk pools. Add disks, remove disks, or change the complete layout of a disk pool.
Vor einiger Zeit wurde ich von Veeam angefragt ob ich ein Live Webinar durchführen möchte. Nun, ich musste da nicht lange überlegen und habe zugesagt. Die Ideen sprudelten nur so aus mir raus. Naja, fast. Um ehrlich zu sein hatte ich plötzlich eine ziemliche Blockade und meine Musse hat sich spontan in den Kurzurlaub verabschiedet…
Es gibt hunderte Themen über die ich gerne sprechen würde. Seien das grössere technische Dinge oder doch eher die kleinen Tipps und Tricks die einem Admin das Leben etwas eifacher machen. Doch vieles wurde bereits in deutsch- oder englischsprachigen Webinars abgedeckt. Und ich wollte auch nicht einfach etwas aufwärmen sondern was neues bringen. Mein aktuelles Thema ist den meisten von euch sicher nicht neu. Jedoch wurde bis jetzt noch nicht im Rahmen eines Live Webinars darüber gesprochen.
Webinar mit dem VMware vExpert: Alles über das Thema VMware vSAN
Über dieses Thema werde ich am Live Webinar sprechen. Das Webinar dauert rund eine Stunde. Stefano Heisig, Senior System Engineer bei Veeam, euch zeigen wie Veeam mit vSAN umgeht und wie man VMs sichern kann. Veeam ist neuerding offiziell für VMware vSAN zertifiziert! Mein Teil wird viele Punkte rund um VMware vSAN abdecken. Und natürlich bleibt auch noch genügend Zeit für Fragen.
Today it was the last day in our VMware vSAN Deploy and Manage course. Nevertheless today we have given everything again. We had a deep dive in designing vSAN solutions, we discussed the key topics in design decisions and also played around with some what-if scenarios. But as every day we kicked off with some review what we discovered yesterday, and again to make for everyone clear what vSAN really is.
Simple, with GUI, all from the web client (with just few clicks)
install vSphere
create a Cluster
set a VMkernel for vSAN
disable HA
claim disks
create disk groups
claim them as cache / capacity tier
enable vSAN
What’s in the default vSAN policy:
FTT = 1
Stripes = 1
No reservation (neither cache nor capacity)
Thin provisioning
What is a Fault Domain:
an area which may can fail
plan to recover impact of Ops
Rack awareness
Site awerness
Availability:
In vSAN there are two states of compliance…
Compliant
non compliant
Absent => wait for 60 minutes, then rebuild
Degraded => rebuild immediately
What-if failures:
Cache disk fails => lose disk group => latency increases
Capacity disk fails => degraded => rebuild => VM back online
Controller => host issue => HA response
Host outtage (complete loss of host) => HA response => VM response
Module 7 Lesson 2 – Troubleshooting
Some topics we covered already yesterday. Today it was also some repetition and a quick overview about troubleshooting and some of the tools we discovered yesterday. There are so many tools for troubleshooting available, either already built-in or community driven, i think the list could be longer. But at least some of the most known tools i will provide you with this list.
vCenter (you don’t say…)
vROPS
esxtop
Wireshark (yes indeed; capture packets on ESXi and analyze them with Wireshark => pcap)
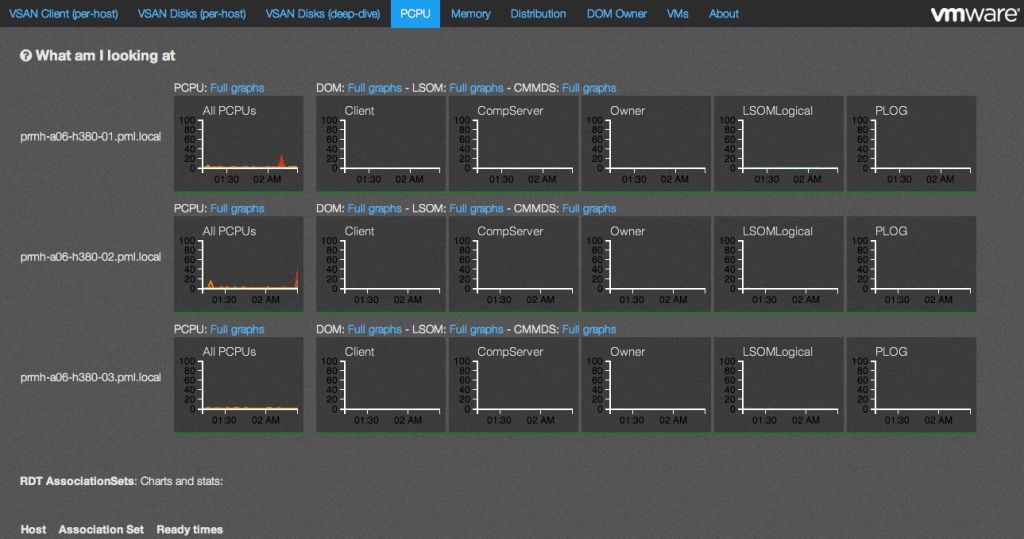
A cool tool indeed is vCheck. It’s based on Powershell scripts and runs against your vSphere infrastructure (there are scripts for other stuff too). You schedule the scripts and you can reveive notifications about changes, issues (before they become a real deal). So when you arrive in your office you already know what’s going on (or what’s not). Also worth to mention is vSAN Observer. It’s already there, just start it and access the built-in webserver to get an overview what’s going on in your vSAN environment.
Module 8 -Stretched Cluster
After doing some work in the labs we talked about design. And having a stretched cluster is also a question of design, how to create a solution which covers rack outtages or even a complete site outtage. You can do that with a stretched cluster. And the failover happens automatic (what may probably not the best solution in every fail over situation…).
When planning a stretched cluster you have to concern about resources. You need 50% spare capacity on both sites (talking about two racks or two sites) in HA admission control. Imagine that one site / rack should keep the other one online, and the stuff which is already running on the secondary site too.
You don’t have to use SRM (Site Recovery Manager) for a failover. vSAN does that for you automatically. If you use SRM then you have to have a recovery plan for each and every VM. Thats a lot of planning and even checks if there are new or changed VMs. Not to think about the costs. You need SRM licenses and a second vCenter license.
Talking about the vSAN witness. A witness is a separate ESXi box. This can be a physical server with ESXi which needs to be licensed. This physical server can’t be a member of a cluster, but it can run some VMs on it. Or you can get a witness appliance, which represents a special ESXi as an appliance, which runs on a ESXi server. This appliance cannot run VMs on it.
You can have a ROBO vSAN cluster in your remote office / branch office which consists only of two ESXi hosts in this cluster. If you’re doing so you have to have a witness host / appliance in your main office site. You always need somewhere a witness to have the quorum in case of an HA event. And remember the 5 heartbeats. In the case of an outtage, after 5 missed hearbeats your host is gone and a failover happens.
Module 10 – Designing a vSAN deployment
That’s not a random list of IT buzzwords, folks. You have to consider these key points when you’re designing a vSAN solution (probably any other scalable solution too).
Availability
Management
Managability
Virtual machines
Performance
Compute
Recoverability
Network
Security
Storage
Let me give you some more things to consider. In the way of designing a vSAN solution you will have to find answers to these questions. Some answers you will get from your customer when talking with him about a solution for his specific needs. Some other answers you will find when you design the solution. And you will find some more questions too…
Requirements (must have / be / do)
“RPO of 15 minutes”
“RTO of 5 minutes”
Location of data / data center
Constraints (design decisions)
“Must work with existing network hardware”
“Must work at this site”
Assumptions
“We have enough bandwith”
Risks
“If the bandwith is not enough => risk of not meeting the SLA”
If you covered the topics above (and the bullet points are just ideas, there are lot more to cover) then you will proceed with the design.
This week i attend the VMware vSAN Deploy and Manage course with Paul McSharry as our instructor. I’m still learning and preparing for my VCP6-DCV which i will catch before new years eve. And there is a helluva stuff to stuff in my brain. This course is not especially for VCP exam, but it will help to answer at least some question about vSAN, which is part of vSphere and this in turn is part of the VCP. So it’s not bad to get some insights.
Day 2
Starting off with day 2 we had a quick review about yesterday, what we did and what we discussed on day 1. We repeated what vSAN is, what you can do with it (and what not; see Pauls review question list further down). Today we worked a lot in the labs to get familiar with some functions, and probably some stuff you wouldn’t do just so in production. We enjoyed also a small outlook to vSAN 6.5 and some of its features in comparison with vSAN 6.2.
After Pauls questions we talked about some basic networking stuff. We discussed load balancing, features of virtual distributed switches and so on. vSAN is set up in just a few clicks. But you have to look for the networking. vSAN is a storage topology which depends on proper configured and well performing network connections. So its a good idea to make the network admins your friends.
Module 5 Lesson 1 – vSAN policies and VMs
A policy is a state config and a specification and it defines basically the SLA. It can be configured at VM or even at VMDK level. The FTT value describes how many hosts can be tolerated to be lost. FTT generates the replicas of your data (how many copies to store). When using stripes we talk about performance. Stripes define the number of physical disks across which each replica of a storage object is striped. It could increase the performance if you add some more stripes. But also the ressource usage will increase. And you will have to have probably more disks.
Another component in vSAN is the witness. It is the tiebreaker for objects. The cluster needs always a quorum to decide what to do in case of an outtage (absent or degraded state). Per default, if a host is absent (the cluster does not know what happend with that host), your data will be replicated after a wait time of 60 minutes. If the cluster is degraded (cluster knows what happend with a dowend host) then the data will be replicated instantly. You can see that the default vSAN policy with FTT=1 is always your safety net. It is recommended not to edit the default vSAN policies but to create new ones and apply those to your vSAN storage / VM / VMDK.
Module 2 Lesson 2 – vsanSpares Snapshots
Is a snapshot a backup? Most people would freak out at this question. No, it’s not a backup. If you want to make backups of your VMs (and thats a damn good idea…) you should use vSphere Data Protection (or other third party products). But VMware did some changes especially for virtual SAN snaptshots. It’s called the vsanSparse Snapshot. A traditional snapshot will be created, but with this new VMDK type. The delta file will be mounted with a virtual SCSI driver, all the read requests are served through the in-memory cache (physical memory from the host) and all writes go directly to disk. It should not create any performance impact and you can keep up to 32 snapshots as long as you want. But don’t do that. Really.
Module 6 – Management (HA & Update)
At the beginning of this module we talked about the maintenance mode and its specific differences in a vSAN cluster. The maintenance mode enables you to take a host out of rotation. This is the normal vSphere (HA / DRS) maintenance mode. The vSAN maintenance mode is slightly different.
When you put a host in a vSAN cluster in maitenance mode then you can choose between three modes:
Ensure accessibility => move objects to active vSAN ressources as needed to ensure access.
Full data migration => move all objects to active vSAN ressources, regardless of wether the move is needed.
Do nothing => move no objects. Some objects might become unavailable.
We discovered in a class discussion that, depending on the amount of data residing on the hosts, it could be painful to put a host in maintenance mode, even if you don’t do a full data migration but just ensure accessibility. It can take some minutes up to some hourse until the host is in maintenance mode. But you can decrease the time needed with adding more hosts, increase FTT and also stripes.
High Availability
Few words about HA (High Availability). If your cluster already has HA configured, then you cannot enable vSAN. You have to disable HA, enable vSAN, and then enable HA again. When HA is turned on, the FDM agent (HA) traffic uses the virtual SAN network. The datastore heartbeat is disabled when there are only vSAN datastores in the cluster. And HA will never use a vSAN datastore for a heartbeat, because the vSAN networking is already used for network heartbeat.
What happens with physical disk failures? In traditional server environments or with a normal SAN you create a RAID array, probably with a hot spare, to ensure immediate disk replacement if a disk fails. With vSAN the redundancy is built logically directly within vSAN (FTT, stripes, witness). Thats the reason you shouldn’t create a RAID array but configure your disk controller to pass-through mode, so vSAN is aware of each physical disk and its state.
Upgrade Process
The upgrade process for vSAN in a few words…
it’s non-disruptive
but it’s I/O intensive
you can’t downgrade a disk group once the upgrade is completed
it needs more than 3 hosts (run the allow-reduced mode => potential risk)
Before you upgrade check the hardware for vSAN 6 support (HCL…). The rest of the upgrade process is straight forward:
First upgrade your vCenter
then upgrade the vSphere Update Manager (VUM)
Afther that upgrade your ESXi hosts to version 6
Confirm that Ruby vSphere Console (RVC) is accessible
Login to Ruby and execute the upgrade script at cluster level
One cool built-in tool we tried out today on day 2 in our course. Its the Ruby vSphere Console (RVC) with which the vSAN Observer can be enabled / started. The process starts a webserver which you then can access via https://vCenterServer_hostname_or_IP_Address:8010. The result looks like this:
The initial configuration is not that easy, but its not a big deal. Enter some commands and you’re good to go. The webserver will stop itself after a runtime of an hour or if you manually stop it with Ctrl + C in the CLI console.
Module 8 – Stretched Cluster
Everyone knows a cluster, a group of servers that act like a single system. A strechted cluster is very similar to a normal cluster, with the difference that you cover two sites with the same cluster (or probably multiple racks in one datacenter), including vMotion, storage vMotion and all other cluster-enabled features.
A stretched cluster helps you to…
do maintenance of a complete site with no downtime
lower RPO for unplanned failures
Setting up fault domains enables you to set…
Rack Awareness (1st is primary site, 2nd is failover, 3rd is witness)
Site Awerness (across sites)
A stretched cluster has some specific requirements (some are also required to setup vSAN itself):
L2 stretched network for vSAN (Multicast)
L3 routed network between witness and vSAN hosts (Unicast)
Less than 5ms network latency for data
200ms latency for witness
500ms latency for ROBO (the two-host vSAN in your remote office / branch office)
10GB links are recommended
If you have less than 10 VMs in your ROBO then you’re fine with 1GB links
Consistent MTU size from end to end
You can imagine the following scenarios when there are outtages in your environment:
Failed site => site failover
Failed host same site => if ressources are good to handle the SLA then same site, otherwise DR in other site
Failed witness => everyone carries on workin because no tiebreaker is needed
Failes network between sites => Restart to preferred site
Failed site with vCenter => Witness comes to use to restart to FD2 site
Conclusion
Today we learned a lot about vSAN in its technical details. With an all-flash solution you get lots of IOPS and performance. With a stretched cluster you can even tolerate a complete site failure. Think about that! VMware Virtual SAN is a really cool storage topology which is easy to setup if everything is prepared correctly (networking!).
Here you can find the other blog posts about the vSAN deploy and manage course:
It is some time ago when i published my last blog article. I wasn’t really in the mood for because i am learning and preparing for my VCP6-DCV. And there is a helluva stuff to stuff in my brain. This week i’m publishing some articles, beginning with this one. Not because i don’t learn for VCP, but because i’m learning right now and because i’m attending the VMware Virtual SAN Deploy and Manage course. Lets call this a recap. My brain is still collecting data and sorting it in the right shelf. This recap helps me with that. But lets start now. You probably don’t wan’t to know whats going on in my brain…
Day 1
Module 1 – Introduction to the course
To break the ice our instructor Paul McSharry started with a short introduction round for all attendees. Paul introduced himself (and his cat too…). I didn’t know him personally. I just knew that he is an expert in his area and a instructor. I heard from other people i know that Paul does his stuff very well. So i expected a good start, and finally the whole day was great.
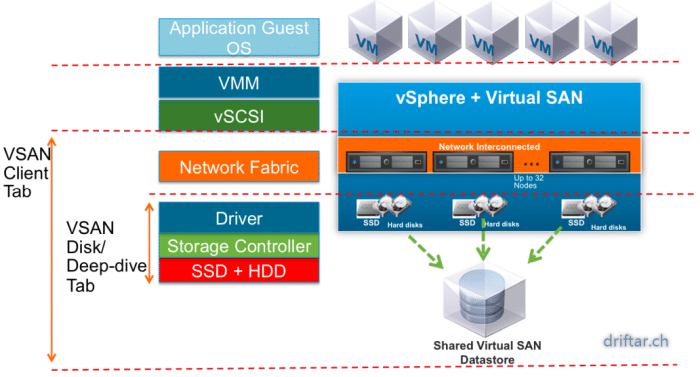
First of all it’s now official that it’s called vSAN (with a small v in front) and not VSAN. VMware recently did a name change on this particular product. It should show that this product (vSAN) is integrated directly into the ESXi hypervisor. vSAN is a policy-driven software-defined storage tier. There are no dependencies on a VM, it runs directly in the hypervisor. We all knew that. You don’t need a special software or plugin to use vSAN, it’s just a matter of licensing. But now the name of the product makes that clear too.
When a customer wants that software defined storage is flexible, easy to use and install, quick and scalable. He doesn’t want to make compromises in performance. And it should also run in my private cloud and in my public cloud too.
Because of my customer size i don’t work often with scalability. I am somehow feeling ashamed for that. We always calculate some reserves into the systems, because we know our customer and always clarify the needs of the customer. Now i’m 100% sure what’s this with scale-out and scale-up. You scale-up when you add some disks to your hosts to increase capacity (or caching) tier in virtual SAN. You scale-out when you add one or more hosts to your (vSAN)-Cluster to increase overall performance and capacity.
Module 2 – Storage fundamentals
In the second module we talked about some basic storage stuff like spinning disks (rotating rust) and SSD’s, about IOPS and so on. We discovered some good points about latency, and why it’s good to have at least flash cache in a hybrid vSAN, or better go all-flash. It doesn’t mean that spinning disks are old school and that you shouldn’t use them. They are great in prize and capacity comparison. Think about an archive system, or a huge backup storage. For this use cases the spinning disks still deliver a fair amount of IOPS.
We took also a short review on RAID levels. It’s always good to know that, and hear it from time to time. When you’re using vSAN you don’t have to create a RAID array on your built-in storage controller. Just make the controller passing-through the disks to ESXi / vSAN and it’s all good. A discussion worth were also some storage protocols like Fiber Channel (FC), iSCSI and NFS. And last but not least the VMware HCL, the hardware compatibility list. Always check this if you build your own vSAN ready nodes, or even if you upgrade firmware (especially disk / controller firmware) on a certified vSAN ready node.
Module 3 – What is vSAN and use cases
Creating vSAN is easy. You can tune, set limits etc. very similar to VMs. Every single I/O gos through the hypervisor. There is no HBA and no fabric in between host and storage. Thats a big plus regarding the storage latency, which means the latency will be decreased massively. With vSAN you use local ressources (CPU, memory and storage). If you have to expand capacity you can easily add more disks (scale-up) or add a host (scale-out). Lets take a look at the ESXi hypervisor. It already comes with HA, DRS, VDP, vSphere Replication. VMware Virtual SAN is compatible with these common features. It’s just a matter of licensing. You are using different storage tiers? You don’t have to with vSAN. It’s policy based. Limit IOPS for noisy neighbors or to guarantee an SLA.
You can build your own vSAN ready nodes (brownfield / specific pods). And you have always to check the HCL. Or you choose from preconfigured vSAN ready nodes from your favorite hardware vendor. HPE, DELL etc. will provide approved solutions. And last but not least there are the DELL EMC VxRail or even VxRack systems, preinstalled and preconfigured.
Use cases
VMware Virtual SAN is since version 6.0 now in production. One of the most uses is for virtual desktop infrastructure (VDI). Customers run also their Exchange servers, transactional data bases and so on with vSAN. There is no right or wrong. If you just wan’t to free up space in your racks and replace old hardware, then you’re good to go. With two height units you can replace four servers and a shared storage system which demand all together at least 10 units. Converged systems are a space saver. And don’t forget about energy savings.
Module 4 – Virtual SAN concepts, requirements, install ckecklist
A vSAN datastore is accessible to all hosts in the vSAN cluster, wether or not they have own local storage. You can have capacity hosts and compute hosts if you want. Other storage topoligies can easily coexist with vSAN, there is no limitation. A vSAN datastore is built from disk groups. Every disk group is a single capacity unit from a host and provides cache and data. You must have one flash disk per disk group and one or more capacity disks. There is a limit of five disk groups per host / node.
You need at least three vSAN hosts / nodes for production environments. Your data (for example a VM) is stored all across the hosts in the cluster. Three components are stored in total; two replicas and a whitness. If a host failure occurs the cluster needs the quorum to decide what to do with your data. Thats the reason why there are three components.
Install checklist
HCL checked?
disk controller in pass through?
host cache and capacity disks?
VMkernel marked as vSAN?
Multicast on network level?
Uplink or VLAN considerations?
1GB or 10GB network connection?
Cluster of three nodes?
Standard switches or distributed virtual switches?
Conclusion
Setting up vSAN is easy as pie. Meet the requirements and turn it on:
setup vSAN networking
enable vSAN on the cluster
select automatic or manual disk claiming
create disk groups if you set automatic disk claiming
And because it’s that easy, the official movie about setting up VMware Virtual SAN is only about three minutes long. There you go.