This week i attend the VMware vSAN Deploy and Manage course with Paul McSharry as our instructor. I’m still learning and preparing for my VCP6-DCV which i will catch before new years eve. And there is a helluva stuff to stuff in my brain. This course is not especially for VCP exam, but it will help to answer at least some question about vSAN, which is part of vSphere and this in turn is part of the VCP. So it’s not bad to get some insights.
Day 2
Starting off with day 2 we had a quick review about yesterday, what we did and what we discussed on day 1. We repeated what vSAN is, what you can do with it (and what not; see Pauls review question list further down). Today we worked a lot in the labs to get familiar with some functions, and probably some stuff you wouldn’t do just so in production. We enjoyed also a small outlook to vSAN 6.5 and some of its features in comparison with vSAN 6.2.
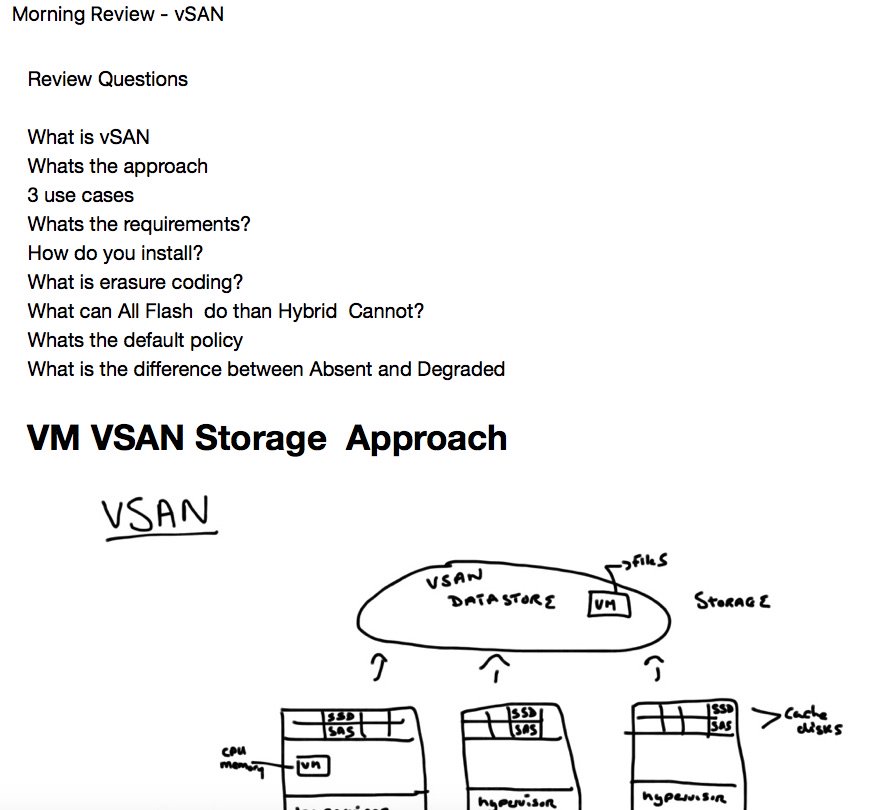
After Pauls questions we talked about some basic networking stuff. We discussed load balancing, features of virtual distributed switches and so on. vSAN is set up in just a few clicks. But you have to look for the networking. vSAN is a storage topology which depends on proper configured and well performing network connections. So its a good idea to make the network admins your friends.
Module 5 Lesson 1 – vSAN policies and VMs
A policy is a state config and a specification and it defines basically the SLA. It can be configured at VM or even at VMDK level. The FTT value describes how many hosts can be tolerated to be lost. FTT generates the replicas of your data (how many copies to store). When using stripes we talk about performance. Stripes define the number of physical disks across which each replica of a storage object is striped. It could increase the performance if you add some more stripes. But also the ressource usage will increase. And you will have to have probably more disks.
Another component in vSAN is the witness. It is the tiebreaker for objects. The cluster needs always a quorum to decide what to do in case of an outtage (absent or degraded state). Per default, if a host is absent (the cluster does not know what happend with that host), your data will be replicated after a wait time of 60 minutes. If the cluster is degraded (cluster knows what happend with a dowend host) then the data will be replicated instantly. You can see that the default vSAN policy with FTT=1 is always your safety net. It is recommended not to edit the default vSAN policies but to create new ones and apply those to your vSAN storage / VM / VMDK.
Module 2 Lesson 2 – vsanSpares Snapshots
Is a snapshot a backup? Most people would freak out at this question. No, it’s not a backup. If you want to make backups of your VMs (and thats a damn good idea…) you should use vSphere Data Protection (or other third party products). But VMware did some changes especially for virtual SAN snaptshots. It’s called the vsanSparse Snapshot. A traditional snapshot will be created, but with this new VMDK type. The delta file will be mounted with a virtual SCSI driver, all the read requests are served through the in-memory cache (physical memory from the host) and all writes go directly to disk. It should not create any performance impact and you can keep up to 32 snapshots as long as you want. But don’t do that. Really.
Module 6 – Management (HA & Update)
At the beginning of this module we talked about the maintenance mode and its specific differences in a vSAN cluster. The maintenance mode enables you to take a host out of rotation. This is the normal vSphere (HA / DRS) maintenance mode. The vSAN maintenance mode is slightly different.
When you put a host in a vSAN cluster in maitenance mode then you can choose between three modes:
- Ensure accessibility => move objects to active vSAN ressources as needed to ensure access.
- Full data migration => move all objects to active vSAN ressources, regardless of wether the move is needed.
- Do nothing => move no objects. Some objects might become unavailable.
We discovered in a class discussion that, depending on the amount of data residing on the hosts, it could be painful to put a host in maintenance mode, even if you don’t do a full data migration but just ensure accessibility. It can take some minutes up to some hourse until the host is in maintenance mode. But you can decrease the time needed with adding more hosts, increase FTT and also stripes.
High Availability
Few words about HA (High Availability). If your cluster already has HA configured, then you cannot enable vSAN. You have to disable HA, enable vSAN, and then enable HA again. When HA is turned on, the FDM agent (HA) traffic uses the virtual SAN network. The datastore heartbeat is disabled when there are only vSAN datastores in the cluster. And HA will never use a vSAN datastore for a heartbeat, because the vSAN networking is already used for network heartbeat.
What happens with physical disk failures? In traditional server environments or with a normal SAN you create a RAID array, probably with a hot spare, to ensure immediate disk replacement if a disk fails. With vSAN the redundancy is built logically directly within vSAN (FTT, stripes, witness). Thats the reason you shouldn’t create a RAID array but configure your disk controller to pass-through mode, so vSAN is aware of each physical disk and its state.
Upgrade Process
The upgrade process for vSAN in a few words…
- it’s non-disruptive
- but it’s I/O intensive
- you can’t downgrade a disk group once the upgrade is completed
- it needs more than 3 hosts (run the allow-reduced mode => potential risk)

Before you upgrade check the hardware for vSAN 6 support (HCL…). The rest of the upgrade process is straight forward:
- First upgrade your vCenter
- then upgrade the vSphere Update Manager (VUM)
- Afther that upgrade your ESXi hosts to version 6
- Confirm that Ruby vSphere Console (RVC) is accessible
- Login to Ruby and execute the upgrade script at cluster level
- vsan.v2_ondisk_upgrade /<vcenter>/<Datacenter>/computers/<cluster>
- Maintenance mode is not required at host level
Now the upgrade utility runs some checks and begins with upgrading the on-disk format.
You can upgrade the disk groups as followed:
- Evacuate all data from the disk group you want to upgrade
- Destroy this disk group
- Rebuild the disk group with the latest on-disk format
- Repeat the steps above for all remaining disk groups
Module 7 – Monitoring vSAN
The monitoring part we have only touched. There are a lot of vSphare built-in and also community driven tools for monitoring vSAN.
Built-in:
- vCenter
- vSphere Web Client
- DCUI
- SSH / vCLI / PowerCLI / ESXicli
- esxtop
- vROPS
- Ruby / vSAN Observer
Community driven:
One cool built-in tool we tried out today on day 2 in our course. Its the Ruby vSphere Console (RVC) with which the vSAN Observer can be enabled / started. The process starts a webserver which you then can access via https://vCenterServer_hostname_or_IP_Address:8010. The result looks like this:
The initial configuration is not that easy, but its not a big deal. Enter some commands and you’re good to go. The webserver will stop itself after a runtime of an hour or if you manually stop it with Ctrl + C in the CLI console.
Module 8 – Stretched Cluster
Everyone knows a cluster, a group of servers that act like a single system. A strechted cluster is very similar to a normal cluster, with the difference that you cover two sites with the same cluster (or probably multiple racks in one datacenter), including vMotion, storage vMotion and all other cluster-enabled features.
A stretched cluster helps you to…
- do maintenance of a complete site with no downtime
- lower RPO for unplanned failures
Setting up fault domains enables you to set…
- Rack Awareness (1st is primary site, 2nd is failover, 3rd is witness)
- Site Awerness (across sites)
A stretched cluster has some specific requirements (some are also required to setup vSAN itself):
- L2 stretched network for vSAN (Multicast)
- L3 routed network between witness and vSAN hosts (Unicast)
- Less than 5ms network latency for data
- 200ms latency for witness
- 500ms latency for ROBO (the two-host vSAN in your remote office / branch office)
- 10GB links are recommended
- If you have less than 10 VMs in your ROBO then you’re fine with 1GB links
- Consistent MTU size from end to end
You can imagine the following scenarios when there are outtages in your environment:
- Failed site => site failover
- Failed host same site => if ressources are good to handle the SLA then same site, otherwise DR in other site
- Failed witness => everyone carries on workin because no tiebreaker is needed
- Failes network between sites => Restart to preferred site
- Failed site with vCenter => Witness comes to use to restart to FD2 site
Conclusion
Today we learned a lot about vSAN in its technical details. With an all-flash solution you get lots of IOPS and performance. With a stretched cluster you can even tolerate a complete site failure. Think about that! VMware Virtual SAN is a really cool storage topology which is easy to setup if everything is prepared correctly (networking!).
2 thoughts on “VMware – vSAN Deploy and Manage course – Day 2”